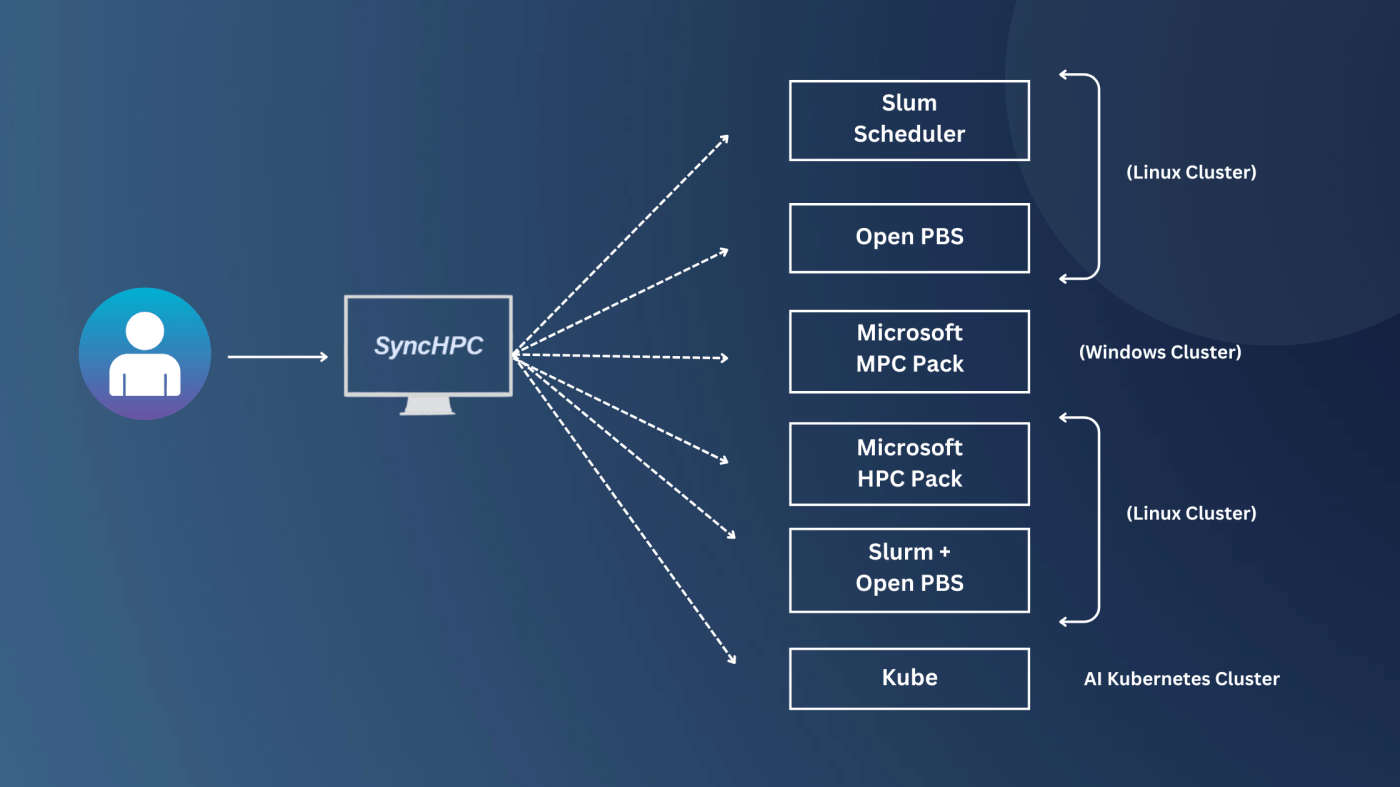
High-performance computing (HPC) & Artificial Intelligence (AI) environments require robust workload management solutions to efficiently allocate resources, schedule jobs, and optimize cluster performance. Different HPC infrastructures and workloads necessitate the use of various job schedulers.
SyncHPC redefines workload management by seamlessly integrating with multiple job schedulers.
A multiple job scheduler is a system that manages the execution of multiple tasks or jobs on a computing platform. It ensures jobs are run efficiently by handling scheduling, prioritization, dependencies, and resource allocation. These schedulers are used in various environments to optimize task execution, improve performance, and manage workloads. By supporting Slurm, OpenPBS, Microsoft HPC Pack, and Kubernetes’ Kube-Scheduler, SyncHPC offers a versatile and unified platform for managing diverse workloads.
Based on the type of HPC infrastructure, SyncHPC can configure the most suitable scheduler for the HPC/AI cluster. SyncHPC also supports multiple deployments within the same platform, enabling different schedulers to coexist. Furthermore, its dual-scheduler capability allows both Slurm and OpenPBS to run simultaneously within the same HPC cluster, enhancing flexibility and efficiency in workload management.
SyncHPC Supports the Multiple scheduler suck as :
1. Slurm : SyncHPC supports the “Slurm” Scheduler to mange the workload on the Linux based HPC Clusters. Slurm (Slurm Workload Manager) is an open-source job scheduler and workload manager designed for HPC clusters. It efficiently handles resource allocation, job scheduling, and execution across multiple nodes, supporting policies like Fair Share, FIFO, and Backfilling. Slurm is a modern, scalable, and fault-tolerant scheduler with better resource granularity and ease of use.
2. OpenPBS : SyncHPC supports the “OpenBPS” Scheduler to mange the workload on the Linux based HPC Clusters. If User OpenPBS (Open Portable Batch System) is an open-source job scheduler and workload manager designed for high-performance computing (HPC) clusters. It manages job submission, scheduling, and resource allocation across multiple nodes, ensuring efficient workload distribution.
3. Microsoft HPC Pack: Microsoft HPC Pack is a high-performance computing (HPC) solution designed for running parallel workloads on Linux & Windows-based clusters. It provides job scheduling, resource management, and workload distribution, similar to Slurm and OpenPBS, but specifically optimized for Windows Server environments as well as for the Linux baased environments. It evaluate, set up, deploy, maintain, and submit jobs to a high-performance computing (HPC) cluster that is created by using Microsoft HPC Pack. HPC Pack allows you to create and manage HPC clusters consisting of dedicated on-premises Windows or Linux compute nodes, part-time servers, workstation computers, and dedicated or on-demand compute resources that are deployed in Microsoft Azure.
4. Dual Sheduler Support (Slurm & OpenPBS): Traditionally, organizations choose either Slurm or OpenPBS based on their infrastructure, user familiarity, and workload requirements. However, SyncHPC offers a unified approach by supporting both Slurm and OpenPBS within the same HPC cluster, allowing users to leverage the best features of both schedulers without the need for separate clusters. SyncHPC implements an intelligent job management system that allows both Slurm and OpenPBS jobs to be submitted and managed on the same cluster.
5. Kube scheduler : For AI/ML workloads, Kubernetes (with Kube-Scheduler) is a powerful alternative to traditional HPC job schedulers. It provides scalability, flexibility, and automation, making it the ideal choice for deep learning, distributed AI training, and model inference. By containerizing AI workloads, Kubernetes ensures seamless deployment, resource efficiency, and end-to-end ML pipeline management across hybrid environments. The Kubernetes scheduler is a control plane process which assigns Pods to Nodes. The scheduler determines which Nodes are valid placements for each Pod in the scheduling queue according to constraints and available resources. The scheduler then ranks each valid Node and binds the Pod to a suitable Node. Multiple different schedulers may be used within a cluster; kube-scheduler is the reference implementation
Conclusion:
SyncHPC provides and support a comprehensive and flexible workload management solution by integrating with multiple job schedulers, including Slurm, OpenPBS, Microsoft HPC Pack, and Kubernetes’ Kube-Scheduler. Its ability to support multiple deployments and dual-scheduler configurations within the same platform enhances resource utilization and streamlines workload management across diverse HPC and AI/ML environments.
By enabling seamless job scheduling, efficient resource allocation, and intelligent workload distribution, SyncHPC empowers organizations to optimize their HPC clusters for maximum performance and flexibility. Whether managing traditional HPC workloads or AI-driven tasks, SyncHPC ensures a unified, scalable, job scheduling experience.

Leave a comment