Performance in High-Performance Computing (HPC) isn’t just about having powerful hardware it’s about how efficiently those resources are managed, shared, and scaled. Platforms like SyncHPC play a crucial role in orchestrating this efficiency. Let’s explore how SyncHPC structures and manages its compute ecosystem through clusters, partitions, and intelligent interconnections that allow jobs to flow dynamically at non-peak hours.
Multiple HPC Clusters
Think of SyncHPC as the central control plane for an organization’s HPC infrastructure. within SyncHPC, you can have multiple clusters. These clusters don’t need to work in isolation they can be managed and monitored centrally by SyncHPC. This centralisation is what enables resource optimization. SyncHPC allows administrators to define a non-peak load window, such as 8 PM to 8 AM, when the overall usage is lower and background optimization can safely take place.
Partitions within Single Cluster
Partitions are created to organise and manage compute resources efficiently within a cluster. Instead of treating hundreds of compute machines (nodes) as one big pool, partitions divide them into logical groups. They are called as ‘partitions’ of nodes. These partitions are not random they are strategically created based on historical usage patterns, team requirements, expected workloads, types of nodes, types of applications, etc.
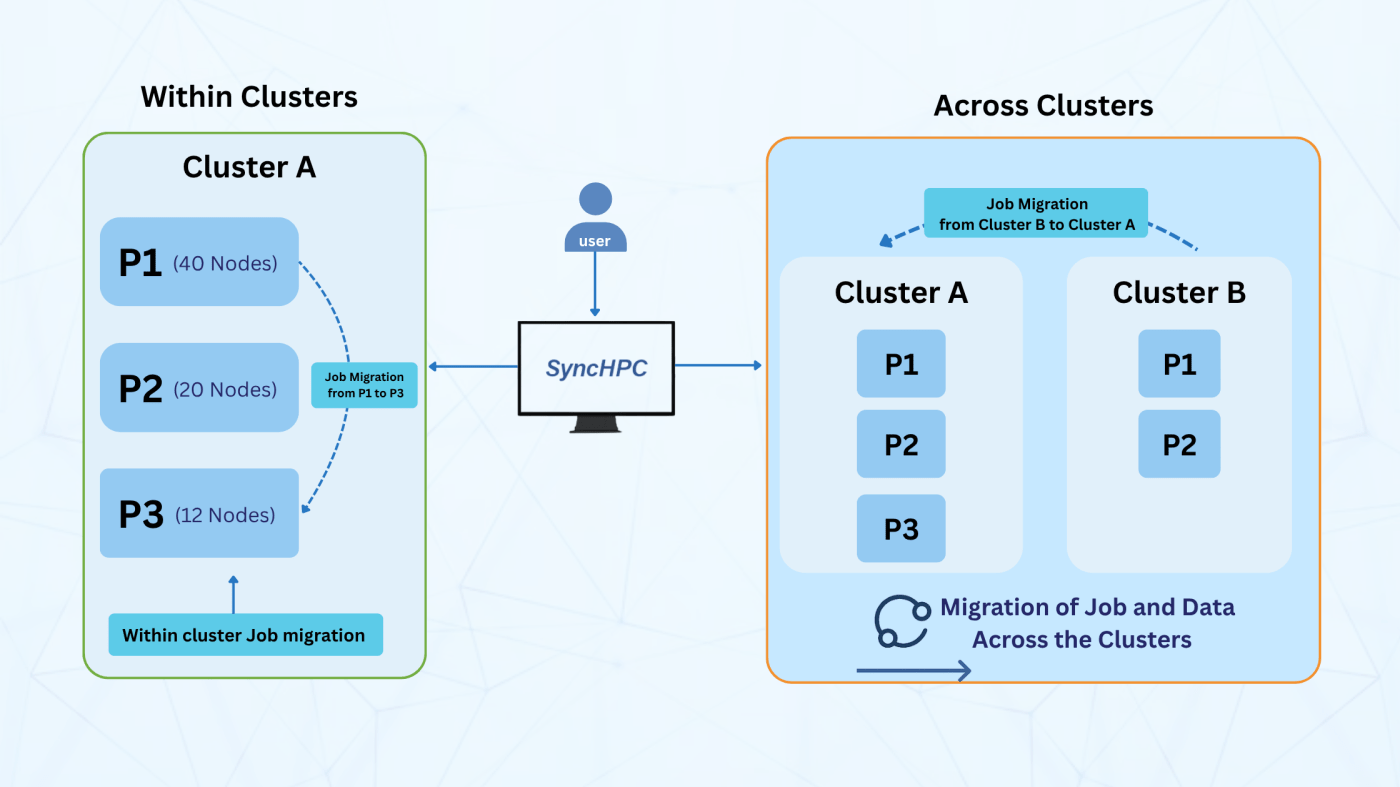
For instance, let’s say partitions are named as P1, P2, and P3:
- P1 may have 40 nodes dedicated to a team that runs an application (say App-1) consistently during the day.
- P2 might consist of 20 machines for another application (say App-2).
- P3 could include 12 machines reserved for research or ad-hoc computational tasks.
In general jobs runs according to the job-scheduler (say Slurm) configured. The administrators define scheduling policies that determine which jobs are assigned to which nodes or partitions. These policies ensure that the peak-time allocation of resources and job-scheduler’s normal behaviour of scheduling jobs.
Need of Time-Based Optimization
During normal hours, the paritions are expected to run at reasonable capacity. Because, they are configured based on the requirements and historical data. However, once the system moves into off-peak hours, (say night time) there may be an imbalance in the utilization. SyncHPC allows the highly loaded partition (say P1) to dynamically share resources with other partitions (P2 & P3), whereas they all remain Static during the normal working time. This collaborative model ensures that no compute resource remains idle, and the overall infrastructure achieves maximum utilization without manual intervention. Also, this temporal flexibility adds another dimension to optimization achieving balance between performance and cost-efficiency across the entire HPC environment.
Migrating Domains: Across and Within Clusters
SyncHPC’s optimization engine operates through migration domains, the logical boundaries that define where workloads can move to achieve better utilization and performance. There are two main types of workload movement that happen seamlessly under these frameworks: within-cluster when a partition (say P1) is heavily loaded, SyncHPC checks for available capacity within the same cluster. If another partition (P2 or P3) has free resources, jobs can be reassigned internally without any data movement, since all partitions share the same storage environment. This inter-partition optimization reduces idle resources and balances compute power efficiently perfect for CPU, GPU, or mixed workloads within a single cluster. Another is Across-cluster If all partitions in one cluster are busy or unsuitable for a given workload, SyncHPC extends optimization across clusters. Here, jobs along with their required datasets are intelligently migrated to another cluster with available capacity. This enables a hybrid, interconnected HPC ecosystem, where multiple clusters collaborate as one seamless environment.
Candidate Machine Specification per Workload
Not all workloads/applications have the same compute requirements. SyncHPC allows administrators to define preferred hardware specifications for each application such as CPU/GPU requirements, memory size, I/O needs, and interconnect bandwidth. When a job is submitted, the scheduler automatically matches it with the most suitable node or cluster ensuring performance alignment and cost optimization without manual tuning.
How It All Connects
- SyncHPC orchestrates the entire ecosystem, monitoring every cluster and partition.
- During off-hours, the system redistribute workloads for even better efficiency.
- Jobs are automatically assigned to the most suitable partition based on workload requirements.
- If a partition is busy, the scheduler reassigns the job within the same cluster without moving data.
- If the whole cluster is busy, the job is transferred to another cluster, with SyncHPC managing data movement seamlessly.
Conclusion
HPC optimization isn’t a one-time tuning exercise it’s a living process where every decision about where and how a job runs impacts overall system efficiency. Platforms like SyncHPC bring this intelligence to life by coordinating clusters, partitions, and data movement under one unified framework.
By enabling smart inter-partition and inter-cluster operations, SyncHPC ensures that workloads are always running in the most optimal environment achieving higher throughput, reduced waiting times, and efficient use of every node across the HPC landscape.
#HPC #ResourceOptimization #SyncHPC #ClusterManagement #InterPartition #HybridHPC #AIWorkloads

Leave a comment