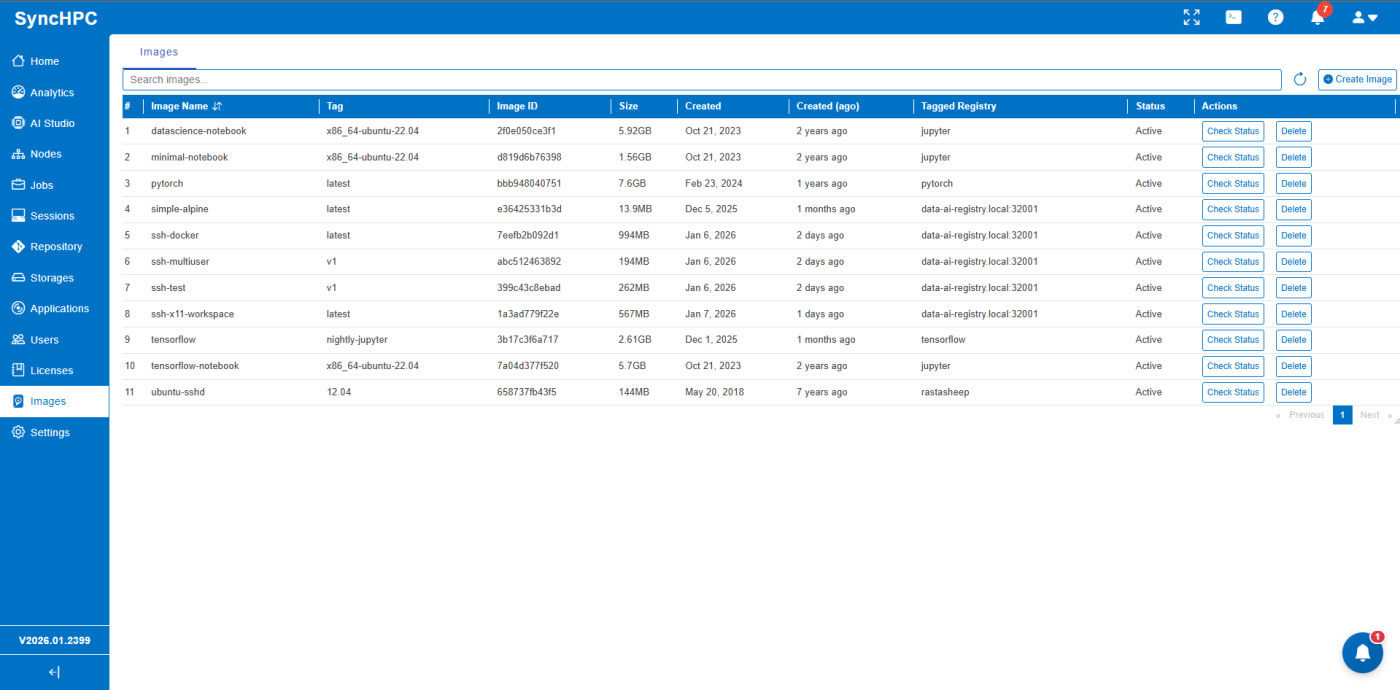
Artificial Intelligence and Machine Learning workloads are fundamentally different from traditional microservices. They are compute-heavy, dependency-rich, iterative, and often executed as batch jobs rather than long-running services. When AI/ML platforms run on Kubernetes whether on-premise or in the cloud one hidden bottleneck quickly appears: Container image management
This blog explains why local container registries and local image workflows, enabled by SyncHPC, are critical for scalable, secure, and fast AI/ML execution on Kubernetes.
These workloads are typically executed using Pods and Jobs, each dependent on a precisely defined container image that encapsulates the complete runtime environment. This includes the required Python runtime, popular ML frameworks such as TensorFlow, PyTorch, and JAX, the necessary CUDA and GPU libraries, and the custom training code, ensuring consistent, reproducible execution across development and production environments.
The Traditional Image Model Breaks for AI/ML. Most Kubernetes setups depend on external container registries. For AI/ML, this model introduces serious limitations.
- Why External Registries impact ML Workflows
- Large images (5–15 GB with CUDA & ML libs)
- Depdency conflicts between ML frameworks
- Slow pulls for every training job
- Internet dependency (problematic for on-prem clusters)
- Security concerns with proprietary datasets and models
- Poor iteration speed during experimentation
For ML engineers, waiting for images to pull is lost research time, and for platform teams, it means wasted GPU cycles.
SyncHPC: Designed Around AI/ML Engineers’ Needs
SyncHPC addresses these challenges by enabling:
Local Container Registry
A registry deployed inside your infrastructure, accessible to all Kubernetes worker nodes.
Local Image Creation
Images are built directly from local code and environments, without pushing to public or cloud registries.
AI/ML-Aware Image Creation
SyncHPC allows AI/ML engineers to create local container images based on their exact requirements, including:
- Specific Python versions
- ML frameworks (PyTorch, TensorFlow, JAX, etc.)
- CUDA and GPU driver compatibility
- Custom system libraries
- Experiment-specific dependencies
Instead of forcing engineers to adapt to generic base images, SyncHPC adapts the image to the engineer
How SyncHpc Enables Custom AI/ML Images
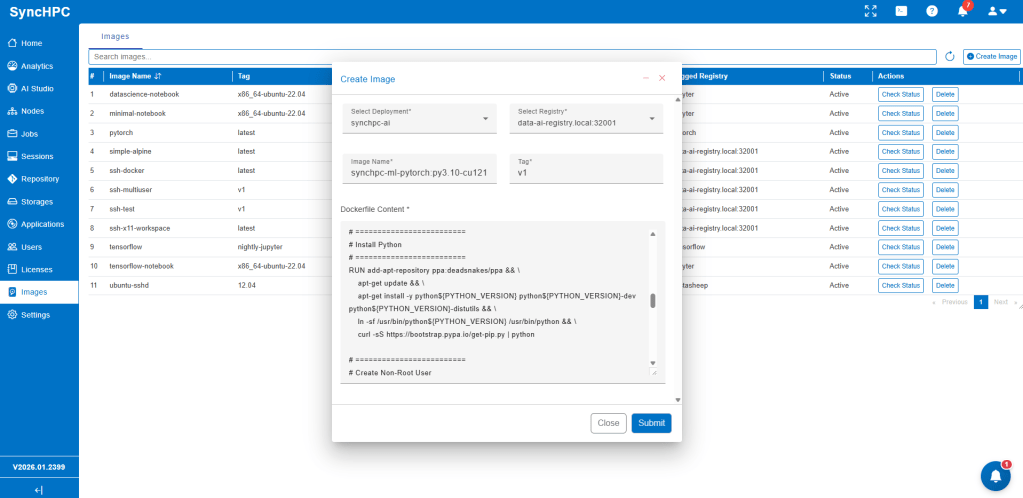
Step 1: ML Engineer Defines Requirements
Each experiment may require a different environment.
Examples:
PyTorch 2.x + CUDA 12
TensorFlow 2.x + specific NumPy version
Custom C++ extensions
Step 2: SyncHpc Builds the Image Locally
SyncHpc:
Builds the image inside the cluster or secure environment
Avoids public registries
Ensures compatibility with cluster GPUs
Step 3: Use the Image in Kubernetes Jobs
The ML engineer submits a AI/ML job referencing the custom image or create pods.
Why This Matters Specifically for AI/ML
Faster Experiments
No repeated multi-GB image pulls.
True Reproducibility
Each model run has a versioned, immutable environment.
Secure by Design
Models, datasets, and IP stay inside the cluster.
Better GPU Utilization
Jobs start faster, GPUs spend more time training not waiting.
What Makes SyncHPC Different for AI/ML
It is workflow-first approach. Container images are treated as first-class citizens, not an afterthought, ensuring consistency and reproducibility across experiments. The platform is purpose-built for batch ML workloads, rather than being optimized only for long-running services, making it ideal for training and experimentation. Additionally, SyncHPC supports per-engineer, per-experiment environments, enabling teams to work independently without conflicts while maintaining full control over dependencies and configurations.
AI/ML infrastructure succeeds when experimentation is fast, environments are reproducible, and GPUs stay busy.
- By enabling:
- AI/ML-specific local image creation
- Secure local registries
- Fast Kubernetes job execution
SyncHPC transforms Kubernetes into a true AI/ML execution platform, suitable for research, training, and enterprise-scale deployments on-premise, cloud, or hybrid. This is not just infrastructure optimization it’s an acceleration layer for AI innovation.

Leave a comment