As AI/ML adoption scales across organizations, the bottleneck is no longer model development it is how efficiently models are deployed, executed, and managed in production environments.
- Most teams encounter the same operational challenges:
- Manual, script-heavy deployment pipelines
- Fragmented tooling across environments
- Difficulty scaling inference workloads
- Lack of standardized workflows across experimentation and production
SyncHPC addresses these challenges by providing a unified platform that streamlines the two critical stages of the AI lifecycle: Model deployment and inferencing built with a strong focus on usability, scalability, and performance.
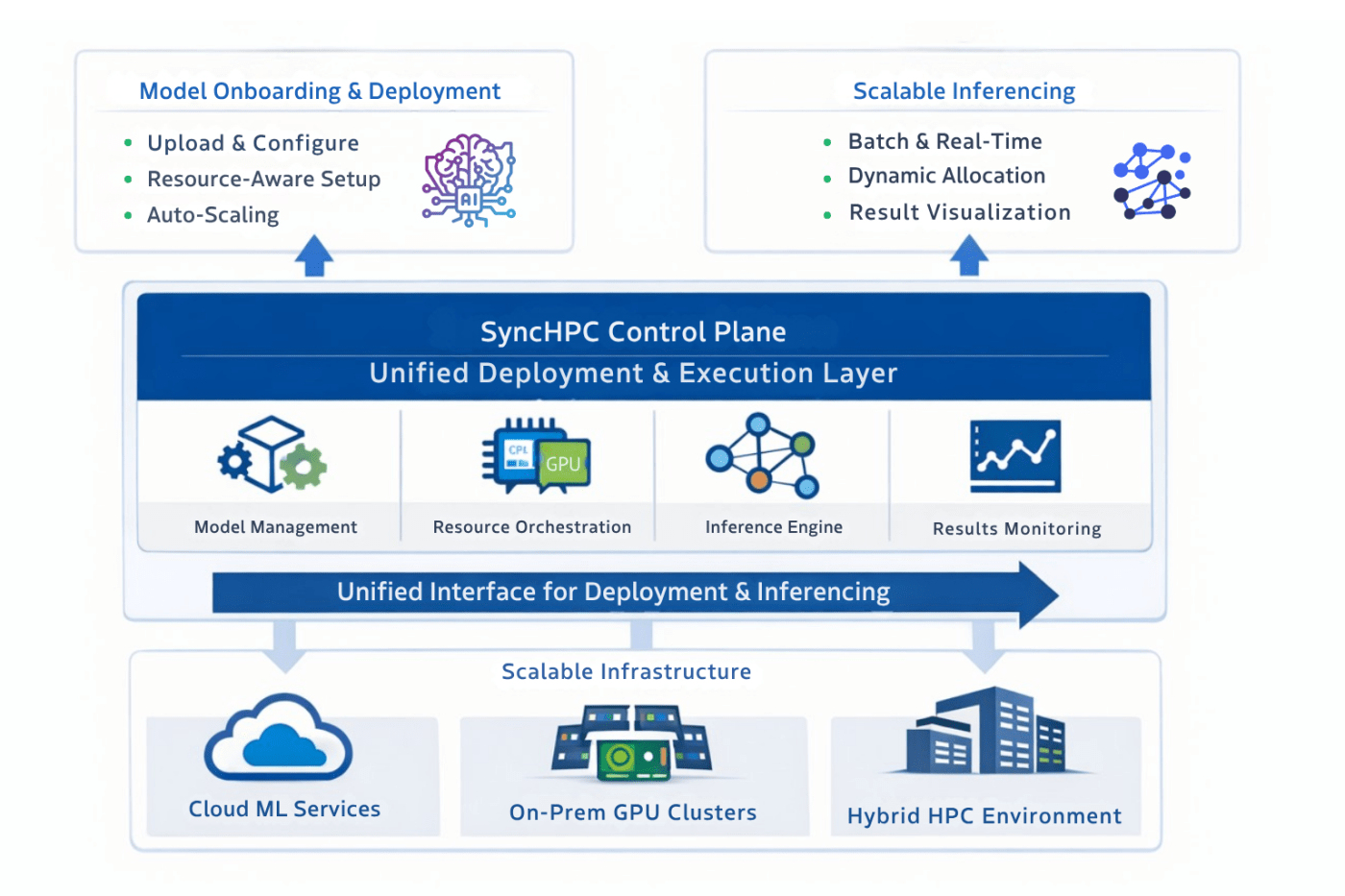
SyncHPC Architecture: A Control Plane for AI Workloads
SyncHPC acts as a control plane above the infrastructure layer, enabling consistent and scalable AI operations.
- It provides a unified system for:
- Model onboarding, serving setup, and deployment
- Resource-aware execution
- Scalable inferencing workloads
- Unified interaction across deployment and execution
- Result handling and visualization
By abstracting underlying systems such as cloud ML endpoints and compute clusters, SyncHPC delivers a consistent operational interface across environments.
Model Deployment: Operationalizing AI Models
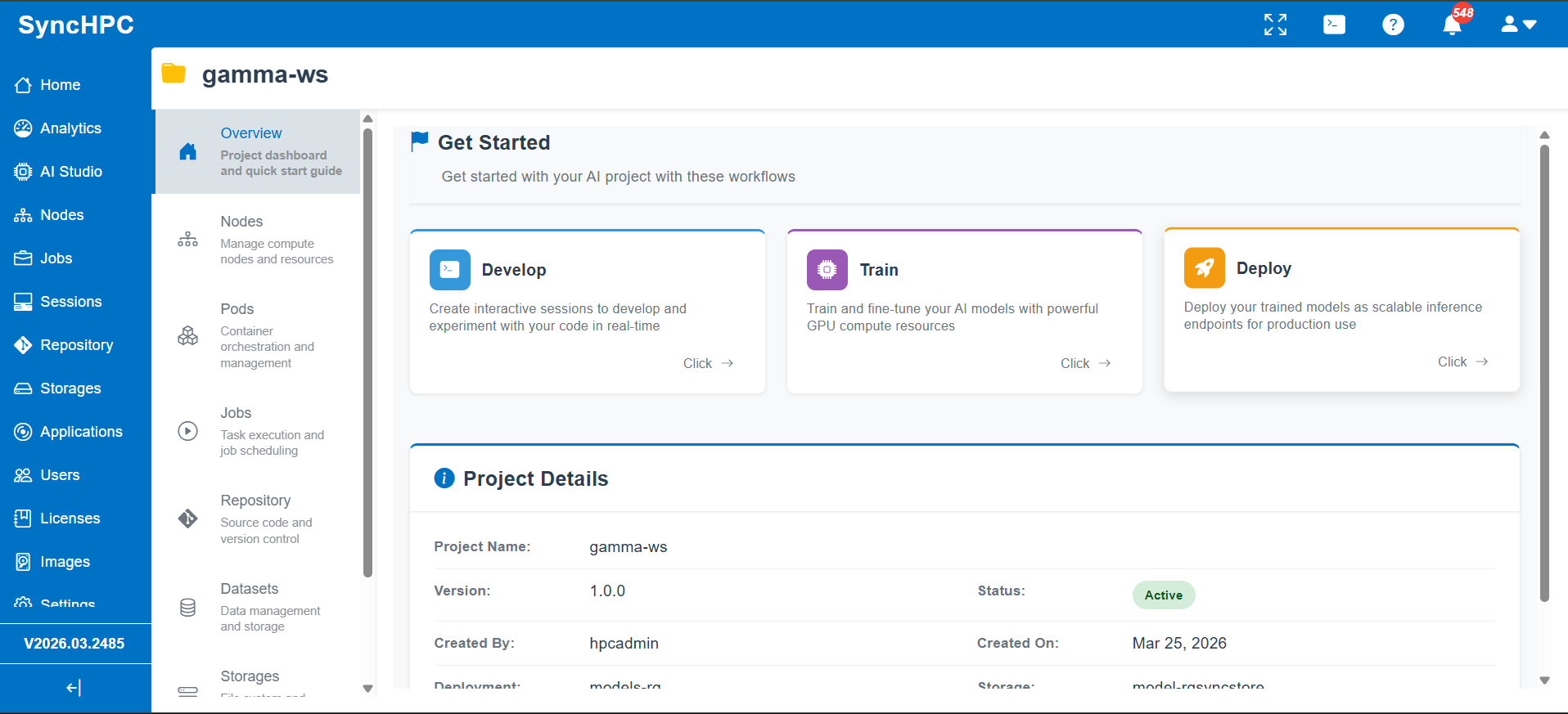
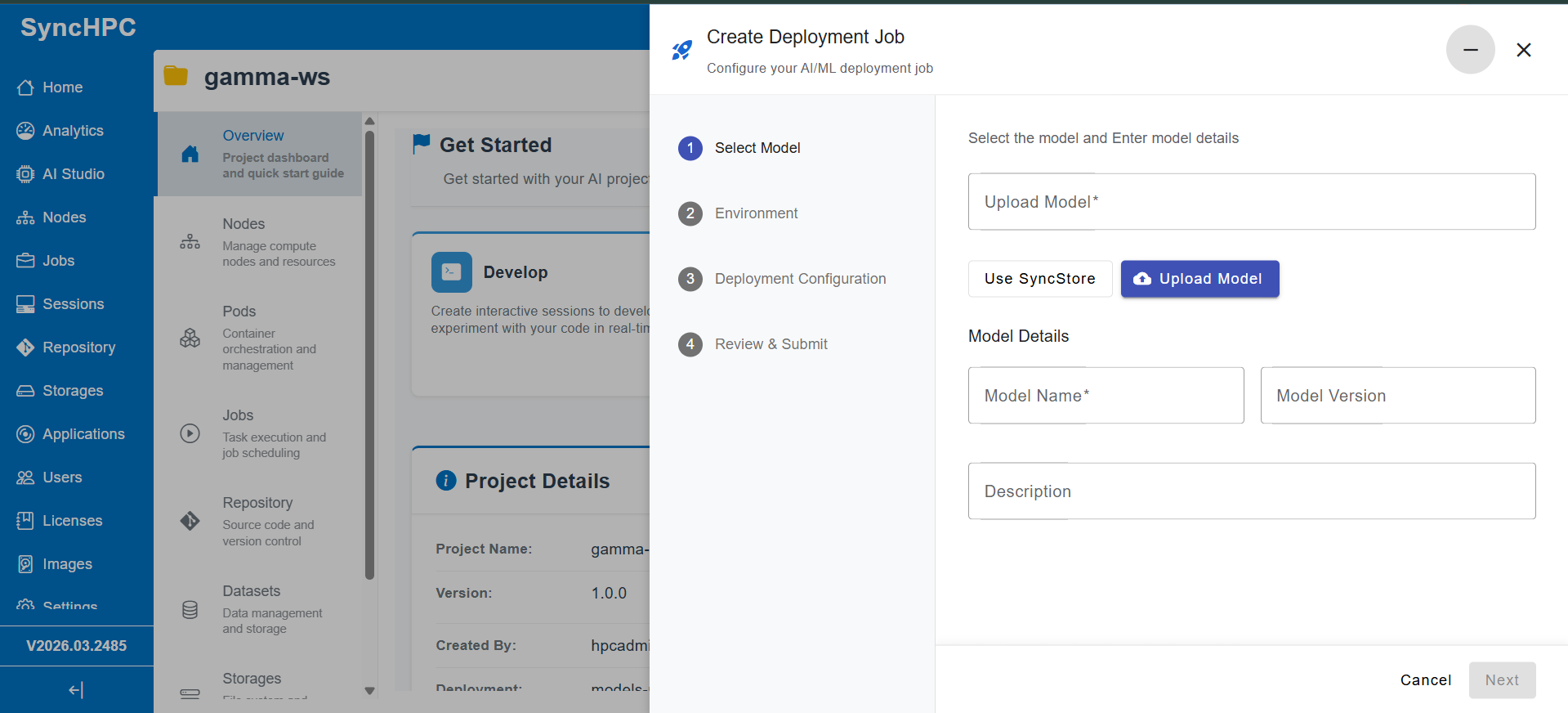
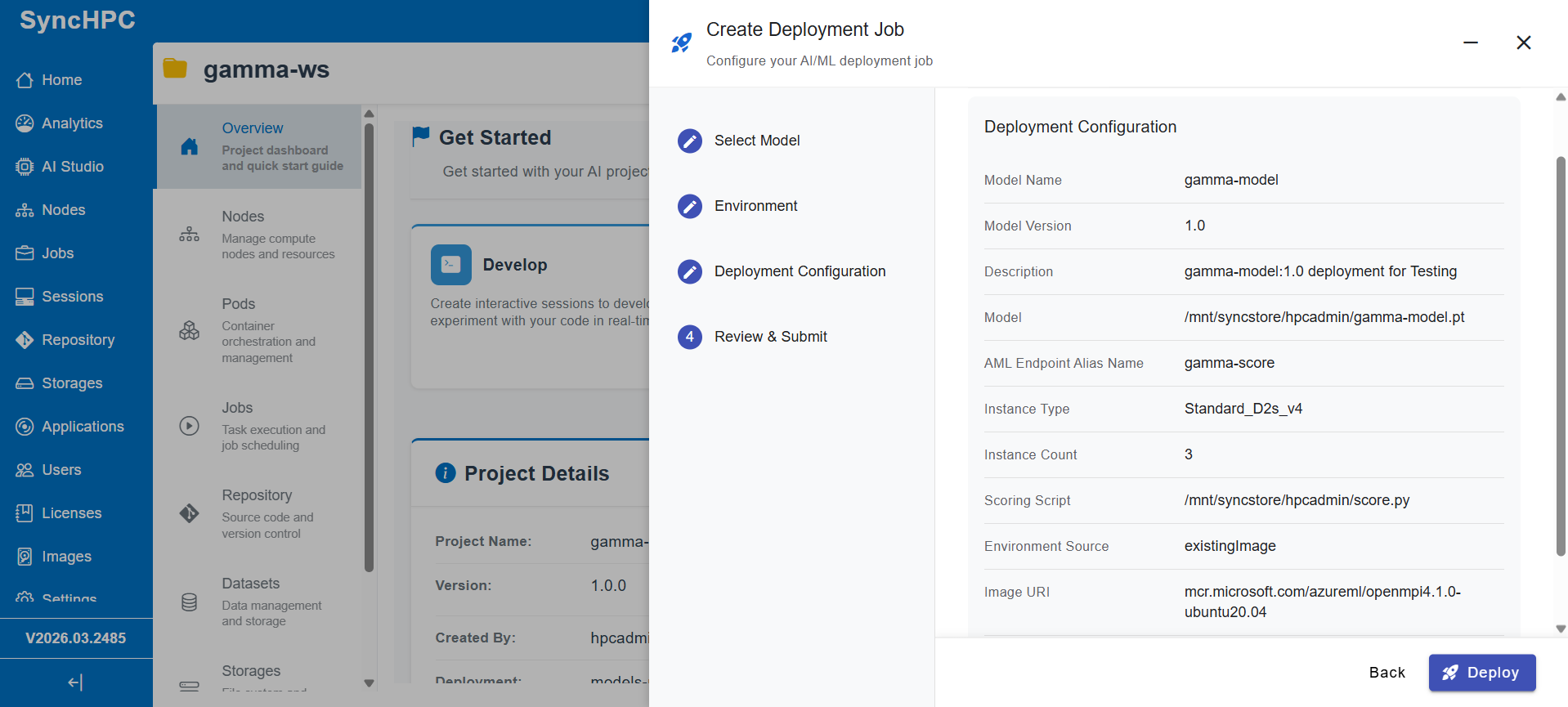
Once a model is trained, it must be deployed in a way that is reliable, scalable, and reproducible.
Challenges in Traditional Deployment
- Custom deployment scripts for each model
- Manual infrastructure provisioning
- Difficulty tuning CPU/GPU resources
- Inconsistent environments across teams
SyncHPC Approach
SyncHPC replaces fragmented processes with a standardized deployment workflow:
- Deploy Anywhere
Choice of your preferred Cloud (Azure/ AWS/ GCP) or On Premise - Unified Deployment Interface
Upload models, configure parameters, and trigger deployments without custom scripting - Resource-Aware Deployment
Define CPU/GPU requirements to ensure optimal performance and utilization - Custom Runtime Environments
Deploy models in user-defined environments with required dependencies - Endpoint Creation
Automatically expose models as ready-to-use endpoints - Built-in Auto-Scaling
Dynamically scale infrastructure based on demand, supporting both steady and burst workloads
Inferencing: Executing Models as Scalable Workloads
In many systems, inferencing is treated as a simple API call. In practice especially in enterprise environments it is a compute workload that must be scheduled, scaled, and managed efficiently.
SyncHPC treats inferencing accordingly.
Core Capabilities
- Immediate Availability Post-Deployment
Deployed models are instantly available for execution, with service discovery and endpoint binding handled automatically - Standardized Inference Execution
Users can provide inputs, configure parameters, and trigger inferencing workflows directly without managing APIs or scripts - Workload-Oriented Execution Engine
Inferencing is executed as scalable workloads, supporting:- Batch processing
- High-throughput execution
- Concurrent workloads
- Dynamic Resource Allocation
Compute resources are allocated per workload, ensuring efficient utilization of CPU/GPU infrastructure - Integrated Result Visualization
Outputs are captured in real-time and presented through an intuitive visualization layer, eliminating the need to process raw responses externally
What Makes SyncHPC Different
1. From Model Serving to Workload Orchestration
SyncHPC does not just host models it orchestrates how they are executed at scale.
2. Resource-Centric Design
Compute (CPU/GPU) is treated as a first-class concept, aligning closely with HPC and hybrid environments.
3. Unified Deployment and Execution Layer
A single platform manages both deployment and inferencing workflows, eliminating fragmented tooling.
Integration with Scalable Infrastructure
- SyncHPC integrates seamlessly with:
- Cloud-based ML services
- Auto-scaling compute environments
- GPU-enabled infrastructure
- For example, integration with Azure ML enables:
- Automated deployment via endpoint APIs
- Elastic scaling of workloads
- Reliable execution environments
Importantly, SyncHPC abstracts these capabilities into a consistent and simplified operational workflow.
Conclusion
AI success depends not just on model accuracy, but on how efficiently models are deployed and executed at scale. By unifying deployment and inferencing into a single platform and abstracting infrastructure complexity, SyncHPC enables organizations to:
- Standardize AI workflows
- Scale workloads efficiently
- Improve resource utilization
- Accelerate time to insight
SyncHPC transforms AI systems from isolated models into fully operational, scalable workloads.

Leave a comment